Same answers, different sources
AI chatbots agree on what to say about candidates — but not where they got it.

In a previous post, we shared how generative AI is becoming a key source of political information and that when chatbots try to persuade, they’re effective.
In our latest analysis using Caucus AI, we ask: How stable are standard AI chatbot responses to questions about political candidates and elections? Do citations actually influence response content?
Users of generative AI tools know that you rarely get the exact same response to a question if you ask it multiple times. This is largely due to two factors:
Temperature, or purposeful randomness setting (some newer models have a setting called “effort” instead, which governs randomness slightly differently), in the model itself that helps models produce more “novel” outputs.
Implementation particulars of large AI models that create variation in responses even when the temperature is set to be non-random.
Setup
Response variation
We took a sample of prompts for different geographies and candidates and ran each prompt 15 times per model at the model’s default temperature/effort level. This allowed us to understand variation in responses.
We measured similarity of responses across 3 metrics:
Semantic similarity: Does a model say the same thing each time?
Keyword overlap: Do models use the same words each time?
Citation overlap and churn: Do responses cite the same source websites?
Citation-content correlation
We scraped 994 candidates’ campaign and official (.gov) websites. We compared the semantic similarity of chatbot responses to candidates’ webpages on the following dimensions:
Whether the candidate’s campaign and/or official webpage was cited by the chatbot
Candidate features: incumbency, partisanship, office level (House, Senate, Governor), and competitiveness
Site features: site type (campaign, official), page type (bio, issues, news, etc.)
Findings
Response content is quite stable.
Overall, models return largely the same meaning even if they use different wording, structure, or formatting.
The cosine similarity of model responses to identical prompts is .94–.95 on average (out of a maximum of 1) across all three models, while metrics of overlap of specific vocabulary are lower.
Responses to more open-ended questions (“What does Jon Ossoff think about important issues in Georgia?”) had more variation than more fact-based questions (“Who is running for Senate in Georgia?”), as did responses to questions about lower-profile candidates and races.
Citations vary widely
The complete list of citations varies significantly from run to run, much more than the information conveyed in the responses.
We identified that each prompt-model combination had, on average:
2.4 core sources that were cited by more than 10 of the 15 responses
3.8 frequent sources cited 4–10 times
12.9 rare citations cited less than 4 times across all runs
Citations matter
Models are drawing from candidate websites. Average cosine similarity between chatbot responses and candidates’ own site content is 0.67, with a median of 0.71. Two-thirds of the closest content matches are biographical pages (career history, background, personal details) rather than policy or issues pages (just 2.2% of best matches). This will likely change as we expand out the set of questions we’re asking the chatbots – right now, our questions focus on candidate backgrounds and biography
Citing a site predicts meaningfully higher similarity. When a response explicitly cites a candidate’s website, it is significantly more similar to that site’s content than when it doesn’t. The effect is large: +12pp for campaign sites and +27pp for official (.gov) sites. This holds across all three models. GPT cites candidate sites least often (35% of responses) but shows the strongest content alignment when it does; Grok cites most often (68%) but with a smaller similarity gap, suggesting it references sites more liberally.
Incumbents score much higher than challengers (0.703 vs 0.629), the largest effect we observed. Incumbents have more web presence, more media coverage, and longer-standing official sites, all of which feed into training data. Challengers, especially lesser-known ones, have responses that diverge more significantly from their own website content.
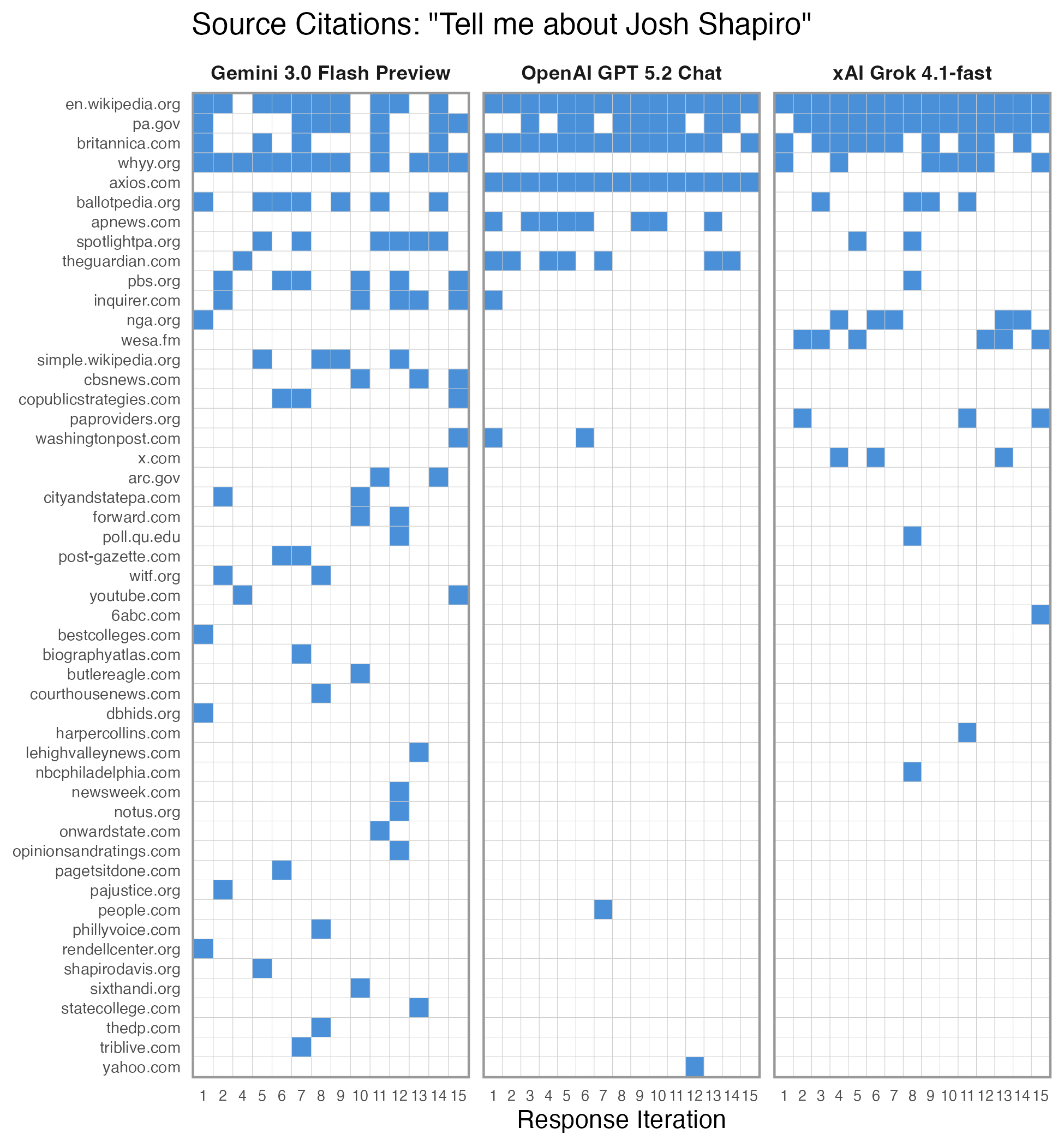
Example: Josh Shapiro
As an example, we can look at the full set of citations for Pennsylvania Governor Josh Shapiro in response to the prompt “Tell me about Josh Shapiro.”
The chart below shows websites cited by each model. Several patterns emerge:
All models cite Wikipedia frequently. It appears in every response from GPT 5.2 and Grok 4.1.
Gemini and Grok cite PA’s NPR affiliate, WHYY, while GPT 5.2 does not.
GPT 5.2 always cites a source from Axios, perhaps driven by OpenAI’s partnership with Axios. The model also cites partner outlets such as the AP and The Guardian.
pa.gov is cited frequently, but Shapiro’s 2026 campaign website (https://joshshapiro.org/) is not cited at all.
What does this mean?
Models generally say the same things in response to factual (“Who is running?”) and biographical questions. However, there is significant variation in the sources models cite for each response. The variation occurs both within models (particularly Gemini) and across models, with some models like GPT appearing to heavily favor certain sources. And, critically, citations seem to matter for content – responses are more similar to the sources they cite.
There are still a lot of open questions. Coming soon, we hope to tackle research like:
Are citations causal? We have established that candidate website citations correlate with response content, but it could be that chatbots may select citations in part based on what their response will be. There is much more work to do to understand how web content changes filter through chatbot responses.
How does this change over time? As new models come out, news outlets adapt to AI-enhanced search, and candidates release new web content, we don’t know how consistent citation patterns may shift over time.